
您的购物车目前是空的!
数字PCR低频突变
描述
数字PCR低频突变检测
【项目介绍】
低频突变是指突变等位基因在大量野生型背景中所占比例较低的遗传变异,常见于肿瘤液体活检、耐药突变监测、FFPE微量样本、细胞系混合样本、基因编辑低比例突变以及模型构建过程中的亚克隆筛查。传统Sanger测序和常规qPCR在低突变丰度背景下容易受到背景噪声、扩增偏倚和定量标准曲线的影响,而高深度测序虽可实现多位点分析,但在单个位点快速验证、低频阳性复核和绝对定量方面仍需结合更直接的检测手段。
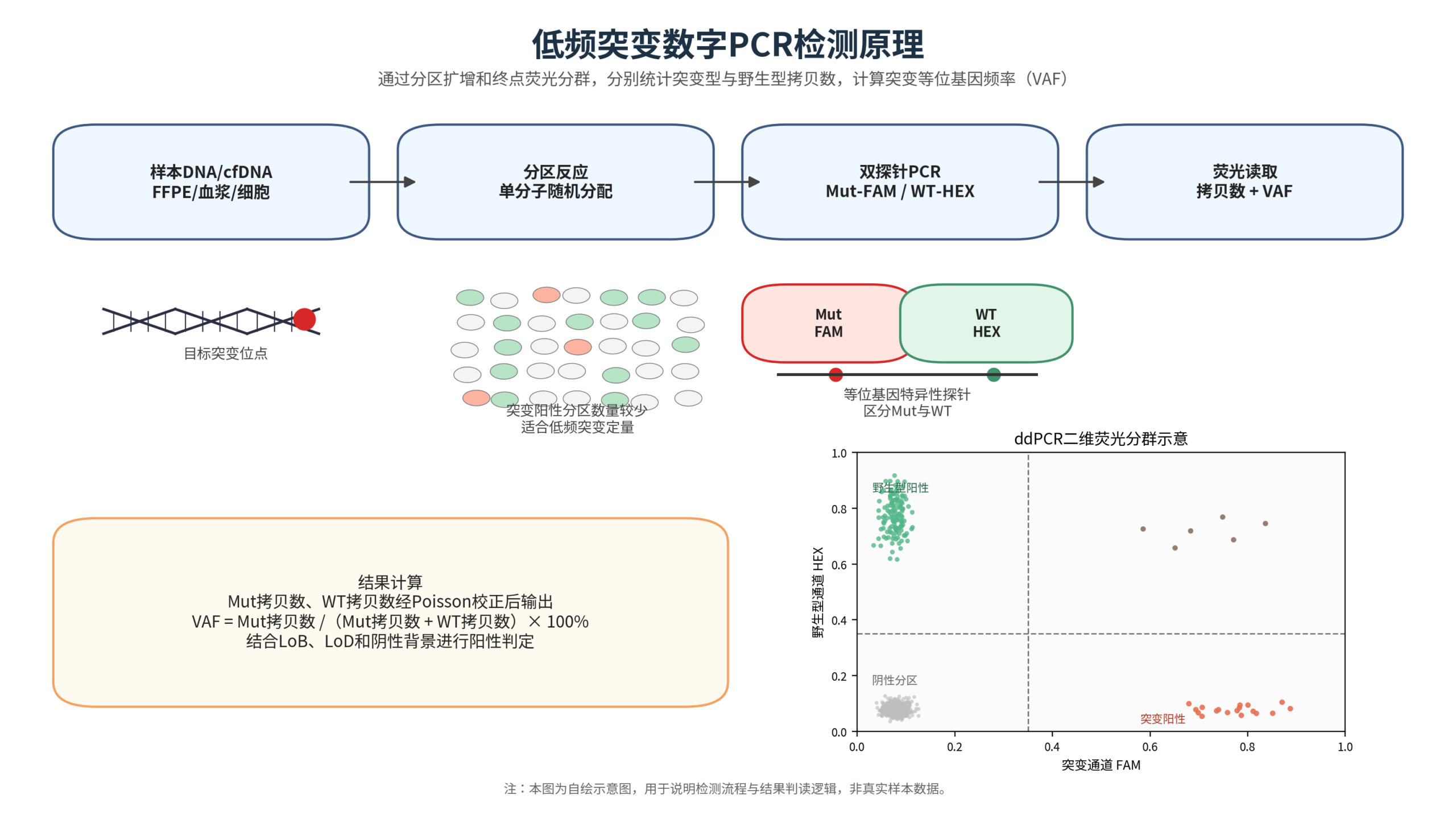
本项目采用数字PCR技术对已知SNV或小片段插入缺失突变进行定量检测。检测体系将反应液分配至大量独立微反应单元中,使突变模板和野生型模板在分区内独立扩增,并通过突变型探针与野生型探针的双通道荧光信号完成分群判读。系统根据阳性分区数进行Poisson校正,直接输出突变型拷贝数、野生型拷贝数和突变等位基因频率(variant allele frequency, VAF)。与相对定量方法相比,数字PCR不依赖标准曲线,适合低丰度突变的绝对定量、动态监测和阴阳性边界样本复核。
低频突变检测的关键不只是“能否检出”,还包括阴性背景下假阳性滴度、最低空白限(LoB)、最低检出限(LoD)、最低定量限、输入DNA量以及突变阳性分区的重复性。因此,本项目在检测前可根据目标位点建立野生型阴性背景、阳性梯度标准品和空白对照,并结合分区数、荧光分群质量和重复孔一致性进行综合判定,避免单纯依据平台理论灵敏度进行过度解释。
图1 低频突变数字PCR检测原理示意图
【检测对象】
• 已知低频SNV或小片段插入缺失突变,如EGFR、KRAS、BRAF、TP53、PIK3CA等热点位点,也可根据客户提供的基因坐标进行定制开发。
• 血浆/血清来源cfDNA、FFPE组织DNA、新鲜或冻存组织DNA、培养细胞基因组DNA、细胞系混合样本及基因编辑样本。
• 适用于人源样本及常见模式动物样本,需明确物种、参考基因组版本、目标坐标、参考碱基和突变碱基。
【适用范围】
| 应用方向 | 说明 |
| 低VAF突变定量 | 对已知突变位点进行绝对拷贝数和VAF计算,适合低丰度阳性样本复核。 |
| 液体活检与耐药监测研究 | 用于血浆cfDNA中EGFR T790M、KRAS等耐药或驱动突变的研究性检测。 |
| NGS/qPCR结果验证 | 对测序发现的低频候选突变进行单个位点快速验证,辅助排除测序噪声。 |
| 细胞模型/混样评估 | 用于细胞系低比例突变、亚克隆筛查、混样污染或基因编辑突变比例评估。 |
【合作方式与样本要求】
• 客户提供目标突变位点信息,包括基因名称、参考基因组版本、染色体坐标、参考/突变碱基或突变序列,最好同时提供上下游约200 bp序列。
• 样本可提供提取好的DNA或原始样本。基因组DNA建议总量≥50 ng;cfDNA和FFPE DNA可根据样本量尽量提供,低输入样本需增加重复孔并降低定量承诺。
• 建议同步提供野生型阴性样本、突变阳性标准品或已知阳性样本,用于阈值设定、背景评估和LoD验证。
• DNA样本建议4 °C短途运输或−20 °C保存运输;血浆和组织样本按常规核酸检测样本运输要求执行,避免反复冻融。
【结果输出】
报告可输出突变型拷贝数、野生型拷贝数、总目标拷贝数、VAF、阳性/阴性判读、重复孔CV、二维荧光分群图及质控说明。若用于正式方法学验证,可进一步给出线性范围、LoB、LoD、重复性和批间一致性结果。
【结果展示形式示例】
| 样本类型 | 输出指标 | 结果解释 |
| 野生型阴性背景 | 突变通道背景阳性分区数、WT拷贝数 | 用于确定LoB和阈值,评估假阳性背景。 |
| 低频阳性标准品 | Mut拷贝数、WT拷贝数、理论VAF与实测VAF | 用于验证不同突变丰度下的检出能力和定量线性。 |
| 待测 | Mut拷贝数、WT拷贝数、VAF、置信区间 | 结合LoB/LoD、重复孔一致性和分群质量给出判读。 |




评价
目前还没有评价